
密集模型的推理能力也能和DeepSeek-R1掰手腕了?
华为利用纯昇腾集群训练出的盘古Ultra,在数学竞赛、编程等推理任务当中,和R1打得有来有回。
关键是模型参数量只有135B,整个训练过程零英伟达含量,而且没有出现损失尖峰。


通过改进的模型架构和系统优化策略,盘古Ultra拥有优异的性能表现和52%以上的算力利用率。
并且有网友表示,训练过程中没有出现损失尖峰这一特征,似乎此前从未实现。

135B密集模型比肩DeepSeek-R1
作为一个参数量135B密集模型,盘古Ultra达到了同尺度密集模型的最优表现,甚至可以与DeepSeek-R1等参数量更大的MoE模型竞争。
在预训练阶段模型的评测中,盘古Ultra在绝大部分英文基准任务和全部中文任务上取得了最佳性能,优于Llama 405B、DeepSeek-V3等baseline模型。
尤其在MMLU、TriviaQA、GSM8K等具有挑战性的数据集上,盘古Ultra展现出了卓越的语言理解和推理能力。
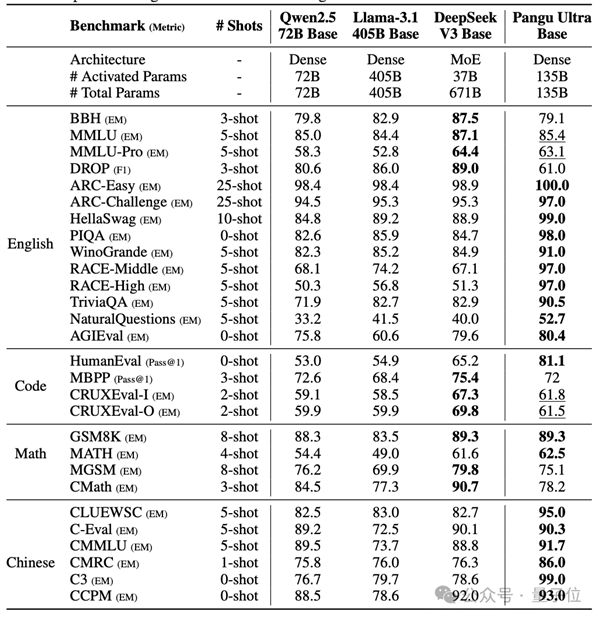
经过指令调优后,盘古Ultra的性能进一步提升,尤其在AIME 2024、MATH-500等数学推理任务和LiveCodeBench等编程竞赛题上达到了SOTA水平。
综合来看,盘古Ultra超越了包括GPT-4o、Mistral-Large 2等强大模型,与DeepSeek-R1等MoE模型竞争激烈。
同时,盘古Ultra在Arena Hard、MMLU-pro等涵盖通用语言理解和推理的评测中也表现优异。

那么,为了实现这样的效果,盘古Ultra采用了哪些关键技术呢?
三明治层归一化架构
如前文所述,盘古Ultra是一款135B参数量的密集模型,使用了94层的网络结构。
盘古Ultra采用了分组查询注意力(GQA)机制,包含96个查询头(query head)和8个键值头(key-value head)。
为了解决训练超深网络面临的不稳定性和收敛困难等问题,盘古Ultra在模型架构上做出了两个关键改进——深度缩放的Sandwich-Norm层归一化和TinyInit参数初始化策略。
传统的Transformer通常使用Pre-LN层归一化,但在深度模型中,Pre-LN容易导致每个子层输出尺度的波动,引发训练不稳定。
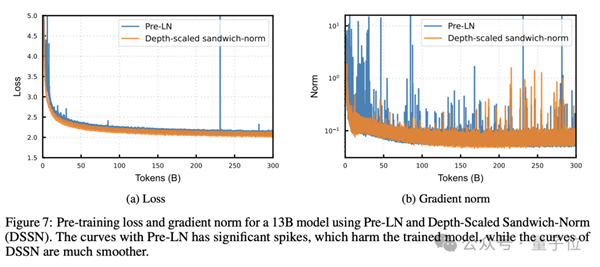
盘古Ultra使用的Sandwich-Norm层归一化,则是在残差连接前对每个子层的输出做归一化,并根据网络深度对初始化值进行缩放,从而有效消除了训练过程中的loss尖峰,使训练过程更加平稳。
用更容易理解的话说,传统方法仅在每个子层的输入进行归一化,但这种方法针对输出也进行了归一化,形成了Pre-Norm + 子层 + Post-Norm的三明治结构。
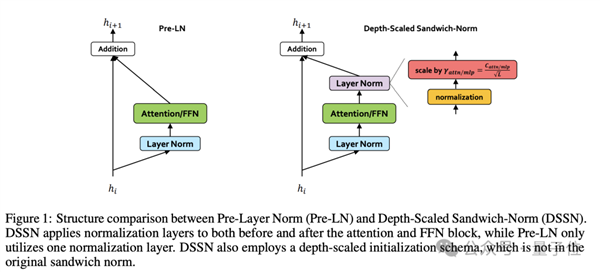
但是,仅仅使用Sandwich-Norm还不足以完全消除深度模型训练中的不稳定性——随着网络层数的增加,每一层的输出尺度仍然可能出现累积性的漂移。
为此,盘古Ultra在Sandwich-Norm的基础上,进一步引入了深度缩放机制,对Post-Norm中的放缩参数γ进行了深度相关的初始化。
至于整个模型的初始化,传统的初始化通常采用的Xavier初始化方法仅考虑模型宽度,而盘古Ultra采用的TinyInit同时依据模型深度和宽度来缩放初始化权重的标准差。
这种初始化方式有助于在前向传播和反向传播过程中,维持各层梯度的方差在一个合理的范围内,避免了梯度消失或爆炸问题,使得训练过程更加稳定,同时也加速了收敛。
实验表明,TinyInit在深度模型训练中取得了更好的收敛速度和下游任务性能;同时针对embedding层,保持权重的标准差接近1也能提升训练稳定性。
另外,盘古团队也针对Tokenizer进行了优化,通过在通用中英文、代码、数学等不同领域分别进行词频统计,再合并去重,最终得到了一个兼顾领域覆盖和编码效率的153376个token的平衡词表。

8192张昇腾NPU训练集群
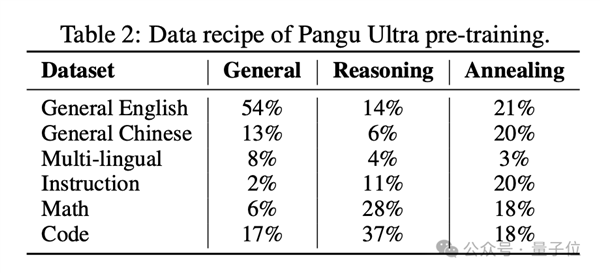
盘古Ultra的整个训练流程主要分为三个阶段——预训练、长上下文扩展和指令调优。
其中预训练又可以分为三个子阶段:
通用阶段:侧重建立语言理解和知识储备,使用了大量中英文通用语料,覆盖网页、书籍、百科等多个来源;
推理阶段:引入更多高质量的数学和代码数据,以增强模型的推理能力。同时还使用instruction数据来帮助模型学习执行任务;
退火阶段:帮助模型巩固知识和推理能力,并强化指令遵循能力。大量使用问答对和人类反馈数据。
研究者们采用了基于规则和模型的数据清洗方法,并设计了curriculum learning策略,让模型循序渐进地学习不同难度的样本。
预训练中使用了AdamW优化器,并动态调整超参数。
预训练后,模型在最长128K的长上下文数据上进一步训练,通过扩大RoPE的基频来实现长序列建模,以增强处理长文档的能力。
最后的指令调优阶则段使用监督微调(SFT)和强化学习(RL)来使模型更好地适应下游任务,学会执行指令并与人类偏好对齐。
训练设施方面,盘古Ultra使用了一个由8192个昇腾AI处理器组成的大规模计算集群。
集群中每个节点包含8个NPU,通过华为高速缓存一致性互联HCCS以全互联的拓扑结构连接,每个NPU配备64GB内存,节点间则通过200Gbps的RoCE(RDMA over Converged Ethernet)网络互联。
为了实现盘古Ultra的高效训练,研究团队还采用了一套系统的并行策略和优化技术。
在并行策略的选择上,盘古Ultra综合考虑了模型的规模、数据的特性以及硬件的拓扑,最终采用了数据并行、张量并行、序列并行和流水线并行等多种并行方式的组合:
128路数据并行,将训练数据分片到不同设备,保证了数据吞吐;8路张量并行,利用设备内部高带宽切分层内张量,实现高效通信;序列并行用于处理超长序列以降低显存压力;8段流水线并行,将不同层分布到不同设备,形成高效的计算流水线。
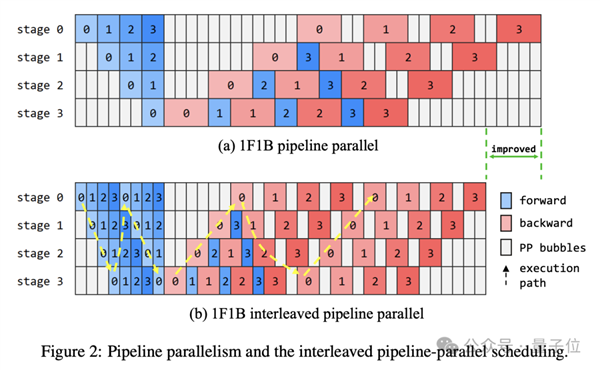
在并行策略的基础上,盘古Ultra还从多个角度对训练系统进行了深度优化。
一方面,通过使用ZeRO(Zero Redundancy Optimizer)分布式优化器,将模型状态分片到不同设备,大幅降低了单个设备的内存占用,在提高数据并行度的同时,确保了每个设备的内存负担在可接受范围内。
另一方面,研究者们通过各种通信和计算优化技术,最小化了通信开销,提升了计算效率:
通过算子融合(Kernel Fusion)将多个小算子合并,减少了内存访问和kernel启动;通过通信计算重叠(Communication-Computation Overlapping)实现通信和计算的深度交织,隐藏通信延迟;MC^2(Merged Computation & Communication)和BOA(Batch Optimization Accelerator)分别对张量并行和规范化层的通信进行了专门优化……
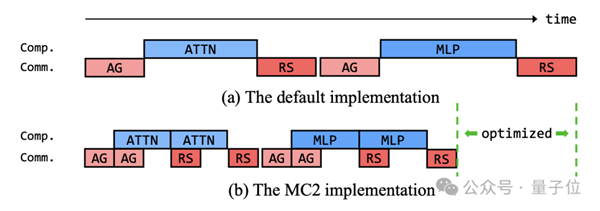
在算法、工程、数据各个层面的精细优化下,盘古Ultra实现了52%以上的算力利用率。
技术报告:https://github.com/pangu-tech/pangu-ultra/blob/main/pangu-ultra-report.pdf
主题测试文章,只做测试使用。发布者:大众参考网,转转请注明出处:https://www.jjrbwx.com/7992.html